Overview
There are occasions where you may want to share only certain parts of a dataset with a client or colleague. One common example is an omnibus-style or syndicated survey. Crunch’s Dataset Views feature allows you to select particular rows and/or variables from an existing dataset and to create a new dataset from them.
What are Dataset Views?
Dataset Views contain a subset of variables and/or rows from a dataset. These views are updated whenever the source dataset is updated, for example, when new responses are uploaded to Crunch. Each View can be shared separately, allowing you to grant multiple clients access to the same data without the risk of the clients accessing the other’s data.

Example use cases
Example 1: a row-restricted View
Imagine you have a dataset that contains survey responses from respondents in different countries, and you want one group of users to see only responses from country A and another group of users to see only responses from country B.
You could create two Dataset Views from the source dataset, each with a row restriction that includes only respondents from a particular country. Then you could put each of those Dataset Views into a different project folder and share each folder with the users you want to have access to the country data. Row restrictions can be defined using the same logical builder as you use when creating a filter in Crunch, meaning that your definitions can be as complex as you need them to be.
Example 2: a variable-restricted View
Imagine you have a dataset that contains 20 questions covering the entertainment industry and 20 questions covering the travel industry, and you want one group of users to see only the entertainment questions and another group of users to see only the travel questions. Syndicated data products with different subscription levels often take this approach.
You could create two Dataset Views from the source dataset, each with a variable restriction that includes only questions from a particular industry sector. Then you could put each of those Dataset Views into a different project folder and share each folder with the group of users you want to have access to that industry sector data.
Example 3: a complete View
Imagine you have a dataset in a folder that is to be made available to a variety of clients who are subscribers to a data product. You could grant all those client users access to a folder with a single dataset, but then you would be reluctant to create any “All user” shared filters, variables, dashboards, etc. because “All users” would mean all clients. Each client would also have to navigate to the location of the shared dataset, which means you couldn’t take advantage of things like client-specific Folder Homepages. Instead, if each client has their own View of the dataset, then shared filters, variables, dashboards, etc. will only be seen by that client and the View can live in the same folder structure as their other datasets.
You could create as many Dataset Views as you have clients, each containing all of the rows and all of the variables. Then you could put each of those Dataset Views into a different project folder and share each folder with the clients who have subscribed to that data product.
Shared artifacts in Views
All users can create and share artifacts — such as variables, dashboards, filters, multitables, and decks — with anyone who has folder permissions to a view. This enables collaboration while ensuring that users don’t need access to modify the underlying dataset. By default, all users share artifacts, but you can use the following instructions to prevent viewers from sharing artifacts on views in a folder.
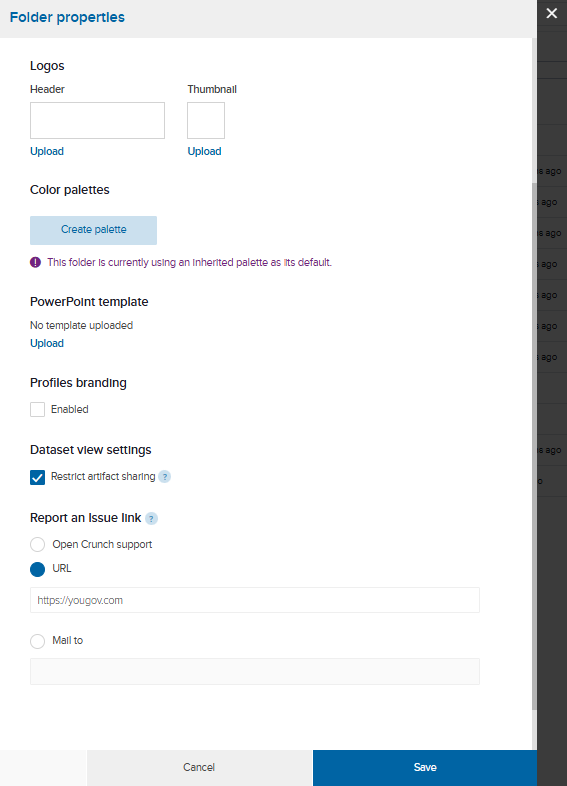
- Locate the folder where your view(s) are saved.
- Click the caret beside the folder name and select Folder properties.
- Under Dataset view settings, check the box beside Restrict artifact sharing.
- Click Save when finished.
Users will no longer be able to share artifacts with other users.
Creating a View
- Open a dataset.
- When your dataset opens, click the down arrow and select Create view (which changes to “Manage views” once one or more Views have been created).
- Select the variables (columns) you wish to include in the new View and click the Next button.
- Select the rows you wish to include using Crunch’s drag-and-drop condition builder and click the Next button (see the help article for more information).
- Give your Dataset View a name (we recommend giving it a different name than the dataset to aid in identification) and a description (optional). Select a location (folder) and click the Finish button.
- The Dataset View appears.
 If you try to include a derived variable in your View definition that requires another variable that is not included in that View, then you will be unable to create that View. Crunch will show you which variables have dependencies and return you to the Variables tab and ask you either to include the required variable(s) or remove the derived variable(s).
If you try to include a derived variable in your View definition that requires another variable that is not included in that View, then you will be unable to create that View. Crunch will show you which variables have dependencies and return you to the Variables tab and ask you either to include the required variable(s) or remove the derived variable(s).




Opening, editing, and deleting a View
To make any changes to an existing View, click the down arrow next to the dataset name in the header and select Manage views:

- A list of all the views that exist for this dataset appears. Click the name of a view to open it:

To edit a view, hover over the row where the view is listed and click the option labeled “edit”:
- The edit dataset view opens, which allows you to make changes to the view:
There are two ways to delete a Dataset View:
- From within a Dataset View: editors can delete a View like any other dataset by going to the “Archive/Delete” tab of the main properties interface.
- From within the source dataset: editors can go to “Manage Views”, hover over a row, and then click the option labeled “delete”:

- After you click 'Delete', you are prompted with the following message. Click Yes to confirm:

The ongoing connection between the Source and a View
A Dataset View is still connected to the source dataset in most ways. Changes made to the source dataset (e.g., changing a label, marking a category as ‘missing’, or deleting a variable) will be seen in the View with immediate effect. That is because a Dataset View is still getting its data and metadata from the source dataset. Additional rows appended to the source dataset will also be seen in the Dataset Views, so long as the new rows meet any row-filter used to define the View. New public variables added to the source dataset will appear in the View so long as they are added to one of the folders included in the View definition. The following are examples to illustrate.
Let’s assume that your source dataset consists of 3 top-level folders and each contains 2 sub-folders. When defining a View, you select the first two top-level folders to be included. You then:
- Create a new public variable that lives at the very top level of the dataset, outside of any folder. In this instance, this new variable will not be included in the View.
- Create a new public variable which you then move to one of the sub-folders of the first top-level folder. Since the first top-level folder was included in the View definition (and therefore everything that lives inside it), the new variable will be included in the View.
- Create a new public variable which you then move to the third top-level folder. Since this folder was not included in the View definition, the variable will not be included in the View.
In cases where only some of the variables inside a folder have been selected, or only some of the sub-folders inside a folder have been selected, additional variables added to that folder will not be automatically included in the View.
Some dataset-level properties are available in Dataset Views independently from the source dataset, including:
- overall population size,
- minimum base size warning/suppression threshold, and
- dataset description.
FAQs about Dataset Views (click to expand)
Who can create Dataset Views?
Only dataset editors can create, edit, or delete Views.
How many Dataset Views can I create from a source dataset?
There is no limit to the number of Views you can create.
Do Dataset Views support Crunchboxes?
Yes, you can create Crunchboxes from Dataset Views just like from a normal dataset.
Do Dataset Views support dashboards?
Yes, you can create dashboards from Dataset Views just like from a normal dataset.
Can I organize my variables into a different configuration in a Dataset View compared to the source dataset?
No. The variables from the source dataset are displayed in the same folders/subfolders in the View as in the source. However, public variables created in the View can be organized into their own folders/subfolders. Variables created in the View cannot be mixed with the source variables.
Do Dataset Views show the latest data automatically if my source dataset is updated?
Yes, Dataset Views continue to query the data in the source dataset, so there will never be a difference in the results between a source and a View.
If I make changes to the source dataset, will these be reflected in the Dataset View?
Generally, yes. If you change labels or change variable types or move variables from one folder to another, these changes will be reflected in the Dataset View. Ensure you are happy for these changes to be seen by all Dataset View users before making changes to the source dataset. There are some exceptions, though. Source datasets and Views do not share the following properties, including overall population size, minimum base size warning/suppression threshold, and dataset description. Another caveat is that new variables created in the source dataset will not appear in the View automatically unless they’ve been added to a folder that was included in the View definition. See the section “Ongoing connection between the Source and a View” above.
If I have a dashboard on my source dataset, will the Dataset Views inherit that dashboard?
No. Dataset Views are created without any dashboard. It is one of the advantages of creating Dataset Views that they can each have their own dashboards.
If I have already created shared filters, custom variables, multitables, decks, and dashboards in the source dataset, will these be included in the Dataset View?
Mostly no. User-generated filters, multitables, decks, and dashboards are not copied to Views. The exception is custom variables, which the View creator can choose to include in the View definition, just like any other variable in the dataset. Custom variables are not included by default, and additional public variables created on the source dataset after the View is created will not automatically become part of the View unless they are added to a folder that was included in the View definition.
Am I charged for Views? Do they count toward my datapoints limit?
Please get in contact with your customer success representative for details on your plan.
If I share my View with a client, can they share it with their colleagues?
Dataset Views have the same sharing rules as regular datasets. We recommend using a folder-sharing model for controlling access to datasets.